









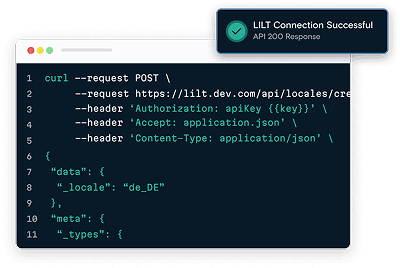
Was LILT ermöglicht
 Verifizierungs-Workflows, abgestimmt auf Ihre Domänenvorgaben und Richtlinien.
Verifizierungs-Workflows, abgestimmt auf Ihre Domänenvorgaben und Richtlinien.- Readiness-Scoring und dynamisches Gating auf Basis von Evaluator-Performance und Aufgabenrisiko.
- Vergleichbare Verifizierungssignale über Sprachen und Regionen hinweg.